До того, як витратити гроші на AI інструменти, консультанта або навчання команди -- дайте відповідь на одне запитання: ваш бізнес готовий?
"Готовий" -- не означає "просунутий". Це означає, що у вас є сировина, яку AI потребує, щоб давати результат: процеси, які люди можуть описати, дані, яким команда довіряє, хоча б одна людина, яка готова вчити нові інструменти, невеликий бюджет на них і культура, де комусь дозволено сказати "давайте спробуємо".
Коли будь-чого з цього немає -- ви отримаєте той самий результат, що сотні інших малих бізнесів: дюжину непотрібних логінів, роздратовану команду і фаундера, який думає "AI просто не працює для нас". Це не AI проблема. Це проблема готовності, і вона виправна.
Це AI аудит готовності, який я проводжу з клієнтами ще до того, як взяти проект впровадження. Пʼять вимірів, кожен оцінюється від 1 до 5, разом 25 балів. Його можна пройти самостійно приблизно за годину. В кінці ви точно знатимете, де ви зараз, що виправляти першим і чи варто запускати пілот цього тижня -- чи провести місяць на прибиранні.
Чому AI аудит готовності важливий
Два роки спостережень за AI впровадженнями в малому бізнесі навчили мене одного уроку: вузьке місце майже ніколи не в AI.
Вузьке місце -- у тому, що ніхто не може описати, як іде процес. Або що дані про клієнтів лежать у пʼяти місцях, і ні в одному не збігаються. Або що команді сказали "нам треба використовувати AI" фаундер, який сам жодного разу не пробував. Або що бюджет поставили, припускаючи, що AI безкоштовний, бо у ChatGPT є безкоштовний тариф.
AI -- не магічний шар, який ви додаєте до зламаного бізнесу. Це множник на те, що ви вже робите. Якщо процеси чіткі -- AI робить їх ще чіткішими. Якщо розмиті -- AI множить розмитість.
AI аудит готовності ловить це до того, як ви витратите гроші. Він дешевий (один день), чесний (бал це бал), і дає конкретний порядок виправлень. Коли я пропускаю його з клієнтом -- перші два тижні проекту все одно перетворюються на примусовий аудит. Краще зробити його наперед і зекономити кошти.
Пʼять вимірів
Кожен вимір отримує бал від 1 до 5. Виміри такі:
- Процеси -- наскільки чітко команда може описати, як робиться робота.
- Дані -- чи доступна і довірена інформація, яку AI потребує.
- Команда -- чи є у команді люди з часом, інтересом або навичками прийняти нові інструменти.
- Бюджет -- чи може бізнес дозволити собі реальні інструменти, а не тільки безкоштовний тариф.
- Культура -- чи дозволить керівництво запустити пілот без комітету.
Ці пʼять разом покривають 95% того, чи вдасться пілоту. Пропустите один -- найкращі AI інструменти у світі не допоможуть.
Вимір 1: процеси (1-5)
Що вимірює: Наскільки добре ваша команда може описати конкретними кроками роботу, яка відбувається у бізнесі щотижня.
Бал 1 -- Задокументованих процесів немає. Ніхто не може пройти через середній понеділок. Робота "просто відбувається", а коли хтось звільняється -- заміна вчиться з нуля.
Бал 2 -- Кілька процесів -- у чиїйсь голові. У вас є пара ключових процесів, у яких одна людина розібралася. Може описати вголос, але нічого не записано. Втрата цієї людини = 3 місяці відновлення.
Бал 3 -- Деякі процеси задокументовані, переважно клієнтські. Є написаний онбординг-процес, або SOP для підтримки, або скрипт продажів. Не все. Внутрішні операції досі імпровізовані.
Бал 4 -- Більшість повторюваних процесів задокументовані, оновлені за останні півроку. Команда може показати документ для будь-якого з топ-10 процесів. Документи використовуються, а не збирають пил.
Бал 5 -- Процесо-орієнтований бізнес. У кожної повторюваної задачі є власник, задокументований процес і метрика. Нових людей навчають за документами, не за спостереженням. Зміни до процесів -- свідомі і відстежувані.
Чому це важливо для AI: AI інструменти потребують конкретних інструкцій. Якщо ви не можете описати процес людині -- ви не опишете його Claude або ChatGPT. Бал 1 або 2 у процесах означає, що ваш перший AI проект -- не пілот, а два тижні опитувань власної команди і запис того, що вони роблять.
Вимір 2: дані (1-5)
Що вимірює: Чи є дані, які AI потребує для роботи, реальними, доступними і довіреними.
Бал 1 -- Хаос у даних. Інформація про клієнтів у семи таблицях, трьох інбоксах і блокноті. Ніхто не знає, яка версія актуальна. "Який у нас CRM?" -- три різні відповіді.
Бал 2 -- Одна основна система, але заповнена наполовину. Є CRM, але оновлені тільки акаунти фаундера. Або є аналітика, але ніхто не довіряє числам.
Бал 3 -- Єдине джерело правди для клієнтів, але операційні дані розкидані. CRM робочий, але фінансові, операційні і проектні дані живуть окремо і не звʼязані.
Бал 4 -- Централізовані клієнтські дані, більшість операційних даних структуровані. За 5 хвилин можна витягнути список топ-50 клієнтів з контактами, статусом і останньою взаємодією. Так само для угод, проектів і інших ключових обʼєктів.
Бал 5 -- Підхід сховища даних. Одне джерело правди для кожного типу запису. Інструменти читають і пишуть у правильні місця. Коли щось розходиться -- хтось помічає за день.
Чому це важливо для AI: Найшвидший спосіб провалити AI процес -- згодувати йому брудні дані. Кампанія холодних емейлів з 30% невалідних адрес виглядає як провал AI, а це провал гігієни CRM. Бот підтримки з неправильними відповідями -- це проблема бази знань, а не бота. Бал 1 або 2 у даних означає: виправляйте дані першими. Навіть один вихідний прибирання піднімає вас на рівень вище і робить кожен наступний AI проект у 10 разів кориснішим.
Вимір 3: команда (1-5)
Що вимірює: Чи є у команді людина з часом, інтересом або навичкою володіти новими AI інструментами після того, як консультант (або ваше майбутнє "я") пішов.
Бал 1 -- Ніхто не зацікавлений. Команда завантажена роботою і вороже або байдуже ставиться до нових інструментів. Попередні розгортання інструментів провалилися через відсутність прийняття.
Бал 2 -- Одна допитлива людина, без часу. Є один член команди, який час від часу користується ChatGPT, але в робочий день у нього немає часу на нове.
Бал 3 -- Одна допитлива людина з годиною на день. Те саме, але фаундер або операційний лід готовий вирізати час, щоб ця людина вчилась і володіла одним новим процесом.
Бал 4 -- Двоє-троє вже експериментують. Кілька членів команди неофіційно використовують AI інструменти. Обмінюються промптами. Зробили хоч одне прискорення, що зберігає час.
Бал 5 -- AI вже щоденна частина роботи для більшості. Команда щодня користується Claude або ChatGPT. Хтось у команді збудував внутрішні автоматизації. Розгортання нових інструментів займає дні, не місяці.
Чому це важливо для AI: Інструменти не впроваджують себе самі. Їм потрібен власник, який користується ними щодня, поки процес не стане звичкою. Бал 1 у команді означає: наймайте або перепризначайте першими. Бал 2 -- збудуйте звичку до того, як будувати процес (дайте допитливій людині годину на день, нічого іншого не міняти, на два тижні).
Вимір 4: бюджет (1-5)
Що вимірює: Чи може бізнес витратити на реальні інструменти і, якщо потрібно, на зовнішню допомогу.
Бал 1 -- Тільки безкоштовний тариф. Нуль бюджету на нове ПЗ поза існуючими підписками. Кожен новий інструмент має довести себе на нулі доларів.
Бал 2 -- До $100 на місяць на нові AI інструменти. Можете дозволити собі Claude Pro або ChatGPT Plus на одного. Все.
Бал 3 -- $100-$500 на місяць. Можете побудувати економний стек: Claude Pro, ChatGPT Plus, Perplexity, один інструмент автоматизації, один інструмент для зображень. Саме тут більшості малих бізнесів варто жити.
Бал 4 -- $500-$2,000 на місяць плюс разові проекти. Можете запустити повний стек на 5-10 людей плюс іноді зовнішня допомога для пілота.
Бал 5 -- Реальний AI бюджет. Є стаття у бюджеті для AI інструментів і радництва. Нові інструменти схвалюються без тримітингового обговорення. Хороший пілот, який себе довів, масштабується на всю команду того самого місяця.
Чому це важливо для AI: Безкоштовний тариф -- це ок для тестів. Не ок для реального продакшну. Ви вдаритеся у ліміт запитів у найгірший момент, втратите роботу, коли сесія закінчиться, або застрягнете на старій моделі. Команда, що намагається запустити продакшн-процеси на безкоштовному тарифі, -- команда, яка відкотиться від AI і звинуватить інструмент. Бал 1 або 2 у бюджеті означає: або починайте з найменшого можливого процесу (одна людина, один інструмент), або підвищуйте бюджет до спроби.
Вимір 5: культура (1-5)
Що вимірює: Чи дозволить керівництво експериментам відбуватися, винагороджувати власників і терпіти невеликі провали.
Бал 1 -- Експерименти заборонені. Кожен новий інструмент потребує комітету. Кожен провал -- ризик для карʼєри. Інновація -- "чиясь чужа робота".
Бал 2 -- Експерименти терплять, але не підтримують. Команда може пробувати у свій час. Нічого формального. Нуль бюджету. Нуль визнання за виграші.
Бал 3 -- Фаундер затвердить пілот. Якщо член команди запропонує конкретний пілот з чітким обсягом -- керівництво скаже "так" за тиждень. Провал пілоту -- не карʼєрна проблема.
Бал 4 -- Пілоти заохочуються і ресурсуються. Фаундер активно питає "що ми можемо запілотити цього кварталу" і дає власнику час і бюджет.
Бал 5 -- Культура орієнтована на експерименти. Малі ставки -- дефолт. Люди відкрито говорять про те, що не спрацювало. Виграші швидко копіюються через компанію.
Чому це важливо для AI: AI пілоти провалюються і успішні на різних частотах, ніж традиційні проекти. 30% провалів на окремих пілотах -- нормально і ок. У культурі, де 30% провалів -- "неприпустимо", люди не запропонують пілоти, а ті, що затвердять, будуть "безпечні" малоамбітні проекти, які ніколи не дають 10x виграшу. Бал 1 у культурі означає, що проблема -- вище вашої оплатної планки. Говоріть з фаундером до того, як говорити з консультантом.
Оціночна шкала
Оцініть кожен вимір від 1 до 5. Підсумуйте.
| Вимір | Бал |
|---|---|
| Процеси | __ /5 |
| Дані | __ /5 |
| Команда | __ /5 |
| Бюджет | __ /5 |
| Культура | __ /5 |
| Разом | __ /25 |
Що означає ваш бал
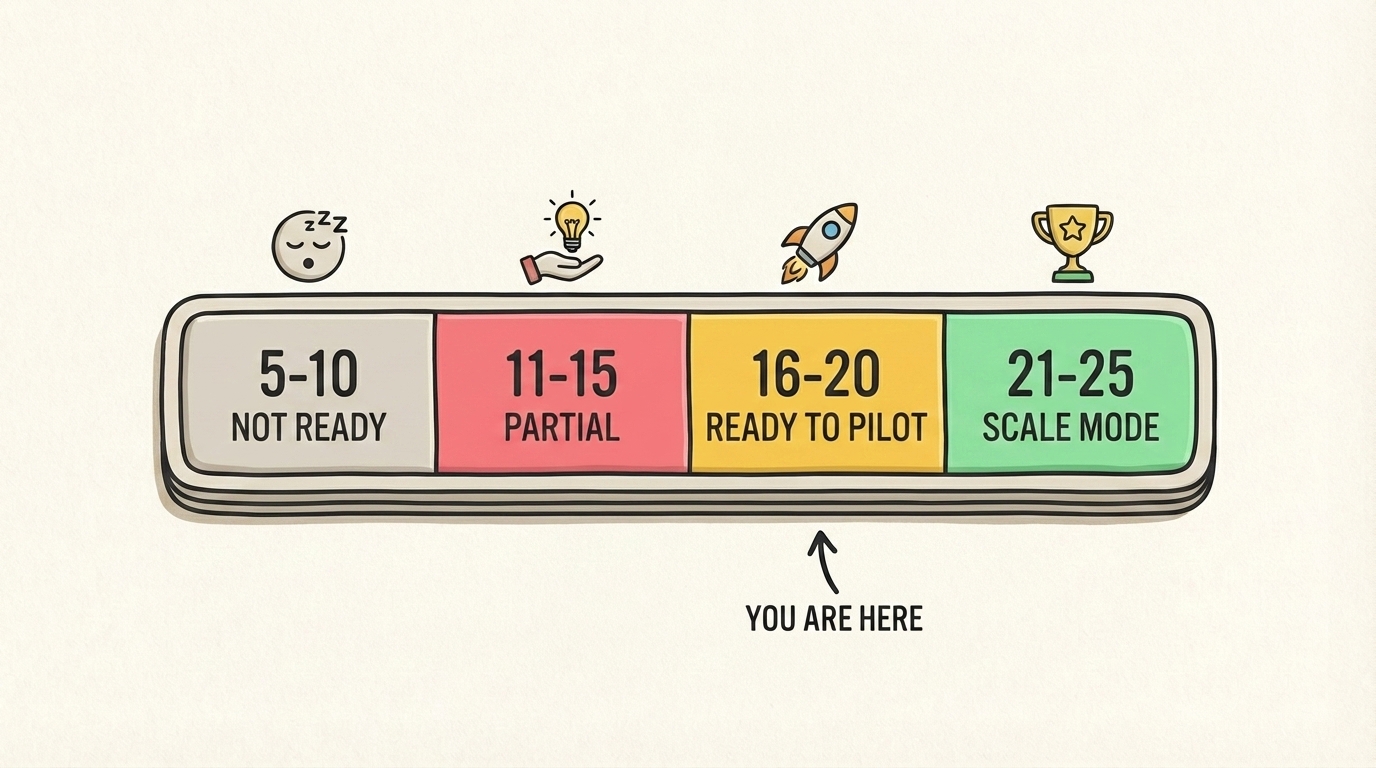
5-10: ще не готові
Ви не готові до AI проекту. Це не присуд -- це реальність, яка економить гроші і нерви.
Проблема: Один або кілька ключових вимірів (зазвичай Процеси або Дані) на рівні 1. Будь-який AI інструмент, який ви купите зараз, буде відторгнутий організмом. Це стан, у якому я ввічливо відмовляюся від проектів, бо взяв би гроші за роботу, яка не закріпиться.
Виправлення: Витратьте 30-60 днів на найслабший вимір. Не на всі. На найслабший.
- Процеси на 1-2: Інтервʼю з командою. Запишіть, що кожна людина робить протягом тижня. Однієї сторінки на людину достатньо. Це само по собі підніме вас з 1 до 3 у Процесах і часто виявить виграші, які не потребують AI взагалі.
- Дані на 1-2: Виберіть одну систему (CRM або клієнтська база) і присвятіть тиждень прибиранню. Видаліть мертві записи. Обʼєднайте дублі. Стандартизуйте поля. Вам не треба data-проект -- вам треба акуратні вихідні.
- Команда на 1: Найміть або перепризначте. Якщо ніхто ніколи не володітиме новими інструментами -- жоден фреймворк не допоможе. AI -- не ваша перша проблема.
- Бюджет на 1: Підняти стелю до $100 на місяць, або прийміть, що ви будуєте на free-tier швидкості.
- Культура на 1: Починайте з однієї людини, яка веде один процес неофіційно. Якщо керівництво не на борту -- формальний пілот помре. Неформальний -- може побудувати кейс.
Поверніться і перескладіть аудит за 30 днів.
11-15: часткова готовність
Можете починати, але маленько і чесно щодо слабкого виміру.
Патерн: Зазвичай трійки скрізь або одна четвірка, збалансована одиницею-двійкою. Бізнес працює. Є чіткі процеси і готова команда, але один з пʼяти вимірів буде битися з вами.
Виправлення: Запустіть один вузько визначений пілот на найсильнішому вимірі, паралельно виправляючи найслабший.
- Якщо Процеси і Команда сильні, а Дані слабкі -- оберіть процес, який не сильно залежить від чистих даних. Написання контенту, нотатки мітингів, сумаризація досліджень -- усе безпечне.
- Якщо Дані і Команда сильні, а Процеси слабкі -- почніть з того, щоб AI документував процеси. Інтервʼю команди, фід у Claude, нехай напише перший чернетковий SOP. Перетворюєте слабкість на перший процес.
- Якщо Бюджет слабкий -- використовуйте безкоштовний тариф для пілота. Оплатіть лише одне місце для власника. Доведіть цінність до витрачання.
На 11-15 перший пілот -- це навчальна вправа. Мета менше "зберегти 10 годин на тиждень" і більше "довести, що AI може тут працювати", щоб керівництво почувалось комфортно інвестувати у наступний. Цільтеся в маленький швидкий нудний виграш.
16-20: готові до пілоту
Ви у солодкому місці для AI аудиту або самостійного першого процесу.
Патерн: Переважно четвірки з, може, однією трійкою. Реальний бізнес з реальними процесами, реальними даними, готовою командою, достатнім бюджетом і фаундером, який дозволить експеримент. Це стан, у якому я бачу більшість 10-50 людинних бізнесів, з якими працюю.
Виправлення: Оберіть процес з найвищим впливом і запустіть чотирифазний цикл. Можна зробити самому за 90 днів або взяти радника, щоб стиснути до 4-6 тижнів.
На 16-20 вам не треба виправляти готовність -- вам треба дисципліна виконання. Ризик не в тому, що пілоти провалюватимуться, а в тому, що ви запустите пʼять одночасно і не закінчите жодного. Оберіть один. Запустіть. Оберіть наступний.
21-25: режим масштабування
Ви поза територією пілотів. Вам не потрібен консультант для першого проекту -- вам потрібен один (або внутрішній операційний лід), щоб утримати від розростання.
Патерн: Переважно пʼятірки. Процеси, дані і команда сильні. Бюджет і культура підтримують експерименти. Це зазвичай SaaS серії А, добре керований сервісний бізнес на 30+ людей або фаундерська команда, яка вже роками робила все правильно.
Виправлення: Припиніть одноразові пілоти і починайте будувати внутрішню здатність. Найміть або підвищіть одну людину, яка володіє "AI системами" як частиною ролі. Будуйте внутрішню бібліотеку промптів, патернів та інструментів, які інші команди можуть перевикористовувати. Встановіть правило: кожен новий процес починається з "чи може AI робити частину?" як реального запитання, не формальності.
На 21-25 ризик не у провалі -- у розчиненні. Ви тепер можете собі дозволити спробувати багато речей, а значить можете ніколи не закінчити жодного. Дисципліна запустити і виміряти один процес за раз тут важливіша, ніж на будь-якій іншій стадії.
Реальний приклад
Один з моїх клієнтів минулого року -- 22-людинне B2B сервісне агентство. Їхні оцінки і що ми зробили:
- Процеси: 3 (клієнтські процеси задокументовані, операції -- хаос)
- Дані: 2 (CRM наполовину, проектні дані розкидані)
- Команда: 4 (двоє допитливих, один з часом)
- Бюджет: 4 (затверджено $800/міс)
- Культура: 4 (фаундер активно питав пілоти)
- Разом: 17
Вони були готові, але слабкою ланкою були дані. Записи клієнтів у HubSpot, а проектні дані -- у трьох Google Sheets і одному Notion. Якби ми спробували "смарт-дашборд статусу клієнта" як перший пілот -- він би провалився, бо даних не вистачало для AI.
Замість цього перший пілот -- щотижневий підсумковий лист продажів для фаундера. Вхід: дані про угоди з HubSpot (чисті), вихід: 500-словне резюме з виграшами, ризиками і наступними кроками. Налаштування -- три години. Економія на тиждень: приблизно 2.5 години часу фаундера. Не величезне, але реальне, запущене за тиждень.
Цей виграш ми використали, щоб виправдати два тижні прибирання даних у Google Sheets і Notion. Після того, як дані стали надійними, другий пілот -- генератор звітів про статус проектів -- пішов за 6 тижнів, зекономив приблизно 8 годин на тиждень на команду і став шаблоном для трьох інших процесів.
Це патерн. Ви не виправляєте найслабший вимір до початку. Ви обираєте пілот, який працює попри слабкість, а потім використовуєте цей виграш, щоб купити дозвіл виправити слабкий вимір. Далі наступний пілот -- вже великий.
Коли проводити аудит самому, а коли кликати радника
Якщо можете відповісти на 25 запитань чесно за годину з ще одним лідером -- проводьте самі. Оціночна шкала не складна. Складна частина -- бути чесним з оцінкою. Якщо ви думаєте, що у Даних у вас 4, бо "у нас є CRM" -- ймовірно у вас 2. Запитайте людину, яка користується CRM щодня, а не ту, що його купила.
Беріть зовнішнього радника для аудиту, якщо:
- Керівництво не згодне між собою щодо балів і потрібен третій голос
- Вже робили неформальну версію, а команда відкинула висновки
- Плануєте витратити понад $50,000 на AI цього року і хочете незалежну перевірку здорового глузду
- Потрібен письмовий звіт для правління
Зовнішній аудит триває близько тижня і коштує $2,000-$5,000. На виході -- одностолінкова оціночна шкала, одностолінкове резюме висновків і пріоритизований список виправлень. Якщо хтось пропонує $25,000 за "AI готовність" -- ви знову платите за слайди.
Що робити з результатом
Як би ви не провели аудит, зробіть це потім:
- Запишіть бал там, де команда його побачить.
- Зобовʼяжіться виправити одну річ у наступні 30 днів, на базі вашого найслабшого виміру.
- Обирайте пілот-процес тільки після того, як виправлення запустилося.
- Перескладіть аудит за 90 днів.
90-денне перескладання -- частина, яку пропускають. Робіть все одно. Побачите, як бал рухається, і дізнаєтесь, чи виправлення працюють.
Як отримати допомогу
Якщо хочете, щоб я провів аудит з вашою керівною командою і видав оціночну шкалу -- замовте 2-тижневий AI аудит. Перший тиждень -- аудит готовності і мапа можливостей. Другий тиждень -- перший пілот. На виході маєте реальний бал, виправлений слабкий вимір і працюючий процес -- все за 14 днів.
Якщо хочете пройти самі -- використовуйте цей пост як шаблон. Також можна прочитати мій гайд по впровадженню AI в малий бізнес, подивитися, як виглядає нормальний AI консалтинг для малого бізнесу, або забрати AI стартовий набір з промптами, якими я користуюся щотижня.
Аудит -- найдешевша річ, яку можна зробити перед тим, як вкладати гроші в AI. Година чесного оцінювання економить місяці "чому це не працює?". Пройдіть, запишіть число, і використовуйте його щоб вирішити, що робити далі.

